Если в процессе бекапа логов по расписанию с виртуальной машины, на которой крутится база данных MS SQL средствами Veeam Backup столкнетесь с ошибкой:
Skipping database located on excluded virtual disk
и при этом никаких исключений не создано в задаче бекапа, то в первую очередь проверьте что у вас не включена фича MPIO на проблемном сервере. Она осталась включенной после того, как сервер был виртуализован из физического, а роль не была удалена. После ее удаления и полного бекапа сервера, бекап логов по расписанию заработал.
Ошибка в задаче бекапа Veeam Agent
Veeam агент версии — 6.1.0.349
Veeam сервер версии — 12.1.1.56
При бекапе агентом одного из физических серверов возникла ошибка:
Error: AgentManagerService: Failed to start agent, Host ‘MBX01’. The remote procedure call was cancelled. RPC function call failed. Function name: [DoRpc]. Target machine: [::1]
В логах Veeam ничего дополнительного не нашел. Для устранения этой ошибки помог перезапуск сервиса VeeamEndpointBackupSvc на проблемном сервере. Причем сервис не хотел останавливаться, пришлось останавливать процесс Veeam.EndPoint.Service.exe вручную через Task Manager
Если недоступна миграция виртуальной машины в vCenter после ее восстановления
Привет!
Столкнулся с проблемой, что после восстановления из бекапа виртуальной машины в vCenter нет возможности ее мигрировать на другой хост или массив. Соответствующий пункт меню просто на просто недоступен. Не понятна причина такого поведения, т.к. с этим сталкиваются не все виртуальные машины, которые были восстановлены. Но есть способ как это починить, вот официальный мануал от VMware — https://kb.vmware.com/s/article/1029926
VMware ESX unrecoverable error. EPT misconfiguration
Столкнулись с проблемой на одном из хостов виртуализации. При миграции с него виртуальных машин на другой хост виртуальная машина с большой долей вероятности перезагружалась. В логах хоста были подобные сообщения:
Error message on <VM_Name> on <HOST_Name> in <Datacenter_Name>: VMware ESX unrecoverable error: (vcpu-2) vcpu-3:EPT misconfiguration: PA 14f11e7f8
Поддержка Vmware обратила внимание, что в логе /var/run/log/vmkernel.log упоминается постоянно одно и тоже виртуальное ядро:
2023-06-02T17:51:18.058Z cpu24:527386)WARNING: World: vm 527386: 8726: vmm0:<VM_Name>:vcpu-0:EPT misconfiguration: PA 2020eb000
2023-06-02T17:51:57.933Z cpu24:527362)WARNING: World: vm 527362: 8726: vmm6:<VM_Name>:vcpu-6:EPT misconfiguration: PA 1a53f87f8
2023-06-02T19:07:30.107Z cpu24:525206)WARNING: World: vm 525206: 8726: vmm1:<VM_Name>:vcpu-1:EPT misconfiguration: PA bf13bf80
2023-06-02T23:10:06.672Z cpu24:535256)WARNING: World: vm 535256: 8726: vmm0:<VM_Name>:vcpu-0:EPT misconfiguration: PA 80578f7f8
2023-06-02T23:11:37.296Z cpu24:535777)WARNING: World: vm 535777: 8726: vmm2:<VM_Name>:vcpu-2:EPT misconfiguration: PA 3651f558
2023-06-03T00:45:52.563Z cpu24:527569)WARNING: World: vm 527569: 8726: vmm3:<VM_Name>:vcpu-3:EPT misconfiguration: PA 14f11e7f8
Оказывается есть KB от Vmware с аналогичной ситуацией. Что делать?
1) Меняем физически процессорные сокеты местами (если у вас конечно 2 физ. сокета) и переусаживаем планки ОЗУ. Я поменял, в логах стали ошибки уже на ядре cpu56. Значит все верно, проблема в процессоре.
2) Меняем процессор (сокет). Мы заменили и ошибка после этого пропала. Проблема решена.
VMware VCSA «dracut: FATAL: FIPS integrity test failed»
Привет!
Вчера на ровном месте начала возникать ошибка в самом начале загрузки appliance с VMware vSphere 7 (7.0.3.01500)
dracut: FATAL: FIPS integrity test failed
![]() Временное решение, чтобы система загрузилась: нажать клавишу «E» в момент загрузки GRUB меню и в конце строки с параметрами загрузки системы написать:
Временное решение, чтобы система загрузилась: нажать клавишу «E» в момент загрузки GRUB меню и в конце строки с параметрами загрузки системы написать:
fips=0
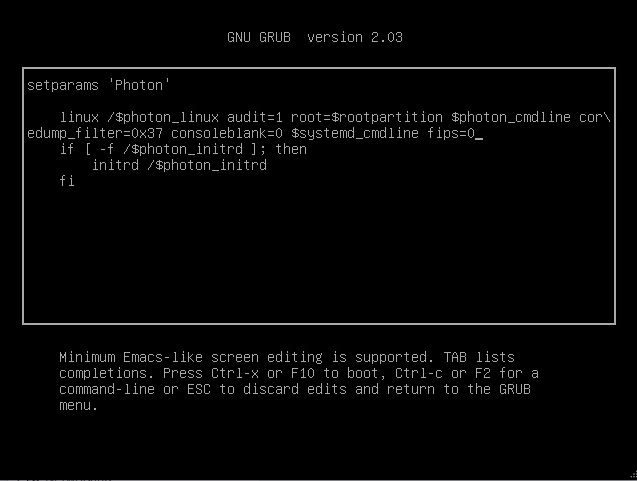
После этого система загрузится как обычно.
При следующей перезагрузке надо будет повторить данную манипуляцию. Пока проблема, получается, полностью не устранена. Буду в ближайшее время обновлять VCSA
P.S. После загрузки системы я проверял официальным методом — FIPS не включен.
Update от 13.09.2023 года: для решения проблемы необходимо:
1) зайти на vcenter под учеткой root
cd /boot/grub2/
vi grub.cfg
Добавить значение fips=0 после systemd_cmdline
2) При следующем обновлении vcenter, после перезагрузки выполнить команду "mkinitrd -q" в консоли vcenter и удалить параметр "fips=0" из загрузчика
Ошибка при in-place upgrade Windows Server
Привет!
Если в процессе обновления до новой редакции Windows Server вы столкнетесь с ошибкой «Windows could not configure one or more system components»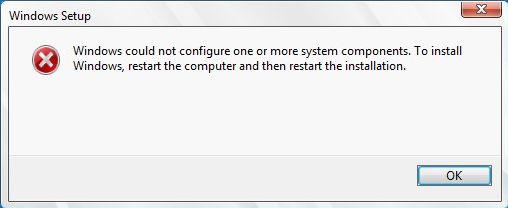
а после отката система покажет ошибку 0xC1900101 — 0x30018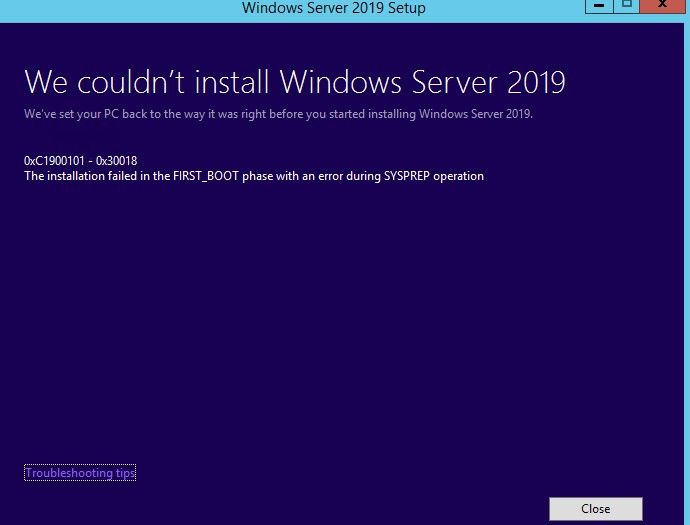
то знайте, что проблема скорее всего в одной из установленных программ. В моем случае это был Crypto Pro CSP. После ее удаления и перезагрузки запускаем обновление заново и ошибки уже не будет. Проверено.
Windows cannot find Microsoft Software License Terms
Если при in-place upgrade операционной системы Windows у вас возникла ошибка «Windows cannot find Microsoft Software License Terms» сразу после этапа выбора операционной системы. Проверьте файл C:\$Windows.~BT\Sources\Panther\setuperr.log (путь может отличаться) на наличие номера ошибки. В моем случае ошибка была с номером 0x060613. Мне помогло, то что нашел решение на сайте technet.microsoft.com, где посоветовали проверить политики безопасности а точнее политику «Manage auditing and security log» узкому кругу лиц, в группу которых не входила учетная запись, которая запускала установщик системы. Я поменял учетку на ту, что имеет более расширенные привилегии и установка прошла успешно.
Veeam Backup: existing backup meta file on repository is not synchronized with the DB
Привет! Недавно столкнулся с очередной проблемой на Veeam Backup and Replication 9.5. Сервер Veeam подвис и я не смог к нему подключиться ни через RDP или RPC, ни через managment интерфейс (HP iLO). Пришлось сервер перезагружать по питанию. После этого я попытался запустить задания бекапа, которые не выполнились за прошедшую ночь и тут посыпались одинаковые ошибки:
Cannot proceed with the job: existing backup meta file 'D:\Backup\test.vbm' on repository 'Scale-Out_Repository' is not synchronized with the DB. To resolve this, run repository rescan.
Я попытался сделать сканирование репозитория но ничего не вышло: ошибка появлялась вновь. При этом задания бекапа логов автоматически запустились через повторный перезапуск сервисов Veeam и начали успешно бекапить SQL. Попытался создать клон задания — оно начало выполняться. Далее начал смотреть сами vbm файлы, точнее их содержание и тут обнаружилось: все файлы, на которые ругался Veeam полностью либо частично повреждены, точнее в них содержится набор нечитаемых символов. Так это выглядело в Notepad++:

В логах бекапа SQL логов нашлось более интересная вещь: По крайней мере стало понятно, что произошел какой-то сбой на сервере, в результате которого вместо информации о бекапах текущего задания в файл сам Veeam начал заносить текст со слетевшей кодировкой.
По крайней мере стало понятно, что произошел какой-то сбой на сервере, в результате которого вместо информации о бекапах текущего задания в файл сам Veeam начал заносить текст со слетевшей кодировкой.
После этого обратился в поддержку Veeam, где они посоветовали удалить файл vbm и запустить задание вновь. О чудо все заработало. Оказывается в случае если в директории нет файла vbm, то тогда Veeam берет информацию о бекапе из базы своей базы данных. Вот такая вот интересная история.
Ошибка восстановления базы данных SQL
Veeam Backup & Replication 9.5 Update 4. Столкнулся с ошибкой при восстановлении базы MSSQL на не оригинальный сервер. После нескольких десятков минут копирования данных (база более 2 ТБ) задание завершалось с ошибкой:
Database restore failed: Failed to read block from file: C:\Windows\TEMP\o1p4abst.bwj\MSSQL.1\MSSQL\Data\work_data.mdf The system cannot find the file specified.
Database restore failed: Failed to read block from file: C:\Windows\TEMP\o1p4abst.bwj\MSSQL.1\MSSQL\Data\work_data.mdf The system cannot find the file specified.
Если глянуть логи на сервере, куда данные восстанавливаются, то там будет следующий текст:
dpl| ERR |Failed to execute DoRpcWithBinary. Command name: 'DoSerialRpc'.
dpl| >> |[NO_SESSION_ERROR] Cannot find session
dpl| >> |--tr:Failed to get session with id {e59b788f-ccea-4656-b68d-3392c8176097}
dpl| >> |--tr:Failed to call DoRpc. CmdName: [DoSerialRpc] inParam: [<InputArguments/>].
dpl| >> |An exception was thrown from thread [3876].
В системном логе была найдена такая ошибка:
Log Name: System
Source: Microsoft-Windows-NDIS
Date: 28.09.2020 17:17:15
Event ID: 10400
Task Category: None
Level: Warning
Keywords:
User: N/A
Description:
The network interface "vmxnet3 Ethernet Adapter" has begun resetting. There will be a momentary disruption in network connectivity while the hardware resets.
Reason: The network driver detected that its hardware has stopped responding to commands.
This network interface has reset 3 time(s) since it was last initialized.
Последний лог и подтолкнул сделать обновление драйверов на виртуальную сетевую карту vmware, т.к. vmware tools были очень древние. И, о чудо, обновление помогло. Следующий раз восстановление прошло успешно!
Ошибка c event id 8194 в VSS

Если у вас после создания теневой копии в Windows Server 2016 возникла ошибка в логе Application «hr = 0x80070005 Access is denied» от источника VSS с Event ID 8194, то знайте, что это стандартная ошибка на свежеустановленной системе и чтобы ее решить надо зайти в настройки DCOM, набрав dcomcnfg и учетной записи Network Service предоставить право локального доступа. Как это сделать смотрите на скриншоте ниже.

После этого нужно перезапустить службу «Система событий COM+» или в английской редакции «COM+ Event System» и затем службу «Теневое копирование тома» или «Volume Shadow Copy» в английской редакции и после этого ошибка из логов пропадет при создании снапшота диска.