При бекапе SQL находящимся на сервере, на котором отключен TLS 1.0 возникает ошибка, указанная в заголовке темы.
Для ее решения у Veeam есть статья , в которой сказано, что нужно создать ключ UseSqlNativeClientProvider типа DWORD со значением 1 в ветке реестра HKEY_LOCAL_MACHINE\SOFTWARE\Veeam\Veeam Backup and Replication.
Самое обидное, что в этой статье ничего не сказано про агенты Veeam, на которых у меня возникла проблема. Для них оказалось нужно создать тот же ключ в другой ветке реестра- HKLM\SOFTWARE\Veeam\Veeam Endpoint Backup.
После этого достаточно перезапустить службы Veeam на сервере.
Veeam BR: Сбор информации о способах бекапа SQL-серверов
Привет!
Понадобилось выяснить как резервируются сервера SQL в Veeam Backup & Replication. Как известно, их можно бекапить несколькими способами
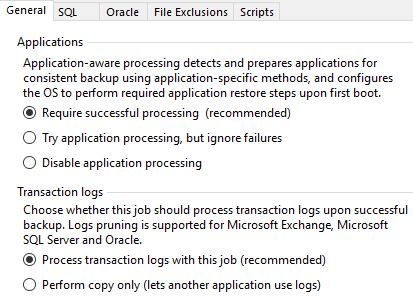
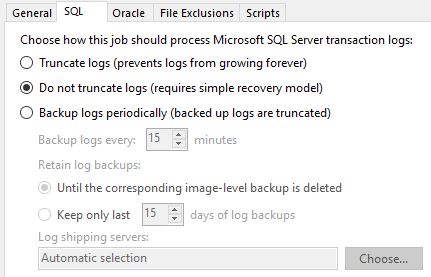 Вариант бекапа «Try application processing, but ignore failures» у меня не используется, поэтому в скрипте он не обрабатывается. Проверка идет только заданий типа «Windows Agent Backup» и «VMware Backup», то есть Linux, Copy Backup и ленты я не рассматриваю.
Вариант бекапа «Try application processing, but ignore failures» у меня не используется, поэтому в скрипте он не обрабатывается. Проверка идет только заданий типа «Windows Agent Backup» и «VMware Backup», то есть Linux, Copy Backup и ленты я не рассматриваю.
Add-PSSnapin VeeamPSSnapIn
$Jobs = Get-VBRJob | where {($_.IsScheduleEnabled -like "True") -and ($_.VssOptions.VssSnapshotOptions.ApplicationProcessingEnabled -like "True") -and ($_.VssOptions.VssSnapshotOptions.Enabled -like "True") -and (($_.TypeToString -like "Windows Agent Backup") -or ($_.TypeToString -like "VMware Backup"))}
foreach ($Job in $Jobs)
{
$Objects = $Job.GetObjectsInJob()
foreach ($Object in $Objects)
{
if (($Object.VssOptions.VssSnapshotOptions.Enabled -like 'True') -and ($Object.VssOptions.VssSnapshotOptions.IgnoreErrors -like 'False'))
{
if ($Object.VssOptions.VssSnapshotOptions.IsCopyOnly)
{
Write-Host "-----------------------------------------------------------------"
Write-Host "Имя задания: " $Job.Name
Write-Host "Имя сервера: " $Object.Name
Write-Host "Тип бекапа SQL: Transaction logs copy only (Lets another application use logs)"
}
else
{
if ($Object.VssOptions.SqlBackupOptions.TransactionLogsProcessing -like 'NeverTruncate')
{
Write-Host "-----------------------------------------------------------------"
Write-Host "Имя задания: " $Job.Name
Write-Host "Имя сервера: " $Object.Name
Write-Host "Тип бекапа SQL: Do not truncate logs (Simple Recovery Model)"
}
if ($Object.VssOptions.SqlBackupOptions.TransactionLogsProcessing -like 'TruncateOnlyOnSuccessJob')
{
Write-Host "-----------------------------------------------------------------"
Write-Host "Имя задания: " $Job.Name
Write-Host "Имя сервера: " $Object.Name
Write-Host "Тип бекапа SQL: Truncate logs (prevents logs from growing forever)"
}
if ($Object.VssOptions.SqlBackupOptions.TransactionLogsProcessing -like 'Backup')
{
$Time_min = $Object.VssOptions.SqlBackupOptions.BackupLogsFrequencyMin
Write-Host "-----------------------------------------------------------------"
Write-Host "Имя задания: " $Job.Name
Write-Host "Имя сервера: " $Object.Name
Write-Host "Тип бекапа SQL: Backup SQL logs every $Time_min minutes"
}
}
}
}
}
VSS asynchronous operation is not completed. Operation: [Shadow copies commit]. Code: [0x8004231f]
При бекапе Veeam агентом физического сервера возникла ошибка:
Error: Failed to create snapshot: Backup job failed.
Cannot create a shadow copy of the volumes containing writer’s data.
VSS asynchronous operation is not completed. Operation: [Shadow copies commit]. Code: [0x8004231f].
Ошибка стала возникать после увеличение диска и перезагрузки сервера.
Команда vssadmin list writers выдавала ошибки подобные этим
Writer name: ‘WMI Writer’
Writer Id: {a6ad56c2-b509-4e6c-bb19-49d8f43532f0}
Writer Instance Id: {7ce8d4ce-3313-4b76-a3c8-254d83320432}
State: [7] Failed
Last error: Timed out
Writer name: ‘MSMQ Writer (MSMQ)’
Writer Id: {7e47b561-971a-46e6-96b9-696eeaa53b2a}
Writer Instance Id: {37a842aa-7da6-4564-af96-e82380de7be4}
State: [7] Failed
Last error: Timed out
Writer name: ‘IIS Config Writer’
Writer Id: {2a40fd15-dfca-4aa8-a654-1f8c654603f6}
Writer Instance Id: {09cbce07-9f96-41fb-9b85-0eed6a1f4432}
State: [7] Failed
Last error: Timed out
Writer name: ‘IIS Metabase Writer’
Writer Id: {59b1f0cf-90ef-465f-9609-6ca8b2938366}
Writer Instance Id: {31eaa04e-0da2-4cde-8dd4-28325a4039d2}
State: [7] Failed
Last error: Timed out
Как вариант, в интернете предлагается перезапустить соответствующие службы, в моем случае это Windows Management Instrumentation, Application Host Helper Service, IIS Admin Service, Message Queuing, но мне это не помогло. Тогда я сделал тестовый снапшот командой vssadmin Create Shadow /FOR=C: иvssadmin Create Shadow /FOR=D: — они прошли успешно.
После этого я перезапустил службу Volume Shadow Copy и ошибка при бекапе пропала!
Надеюсь эта статья вам поможет.
Время хранения резервной копии при экспорте или при VeeamZIP в Veeam BR
Как можно узнать время на которое оставили бекап при его экспорте 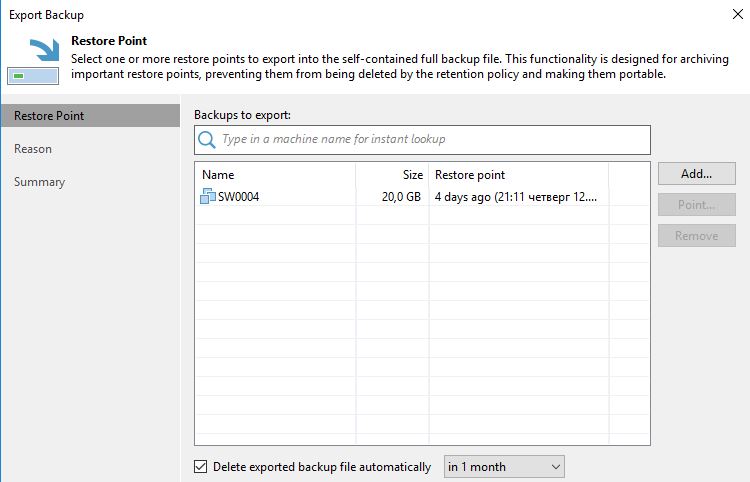
или при VeeamZIP?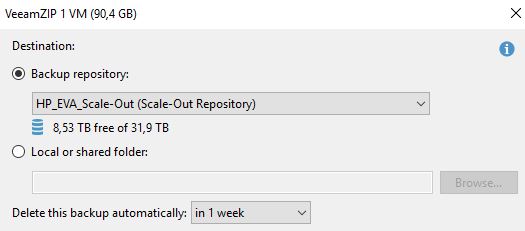
Интерфейс Veeam не позволяет эту информацию получить.
Да, можно это поглядеть в логах History-Restore-Export, но это не совсем удобно, если процесс экспорта бекапа был очень давно.
Как же посмотреть эту информацию:
1) для экспортированного бекапа заходим в Backups — Disk (Imported) и в названии Job Name будет отображаться второй датой время удаления бекапа (Первая дата — время экспорта)
2) Для VeeamZIP в разделе Home — Backups — Disk (VeeamZIP) это время не отображается (только время запуска VeeamZIP), поэтому нужно зайти в базу данных Veeam BR и в таблице dbo.Backup.Model.VeeamZIPRetention в столбце retain_datetime будет дата удаления архива. Сам бекап, который будет удален, будет отображаться в столбце target_file. В этой же таблице отображается информация о времени хранения бекапов при экспорте. У них значение в столбце target_file пустое.
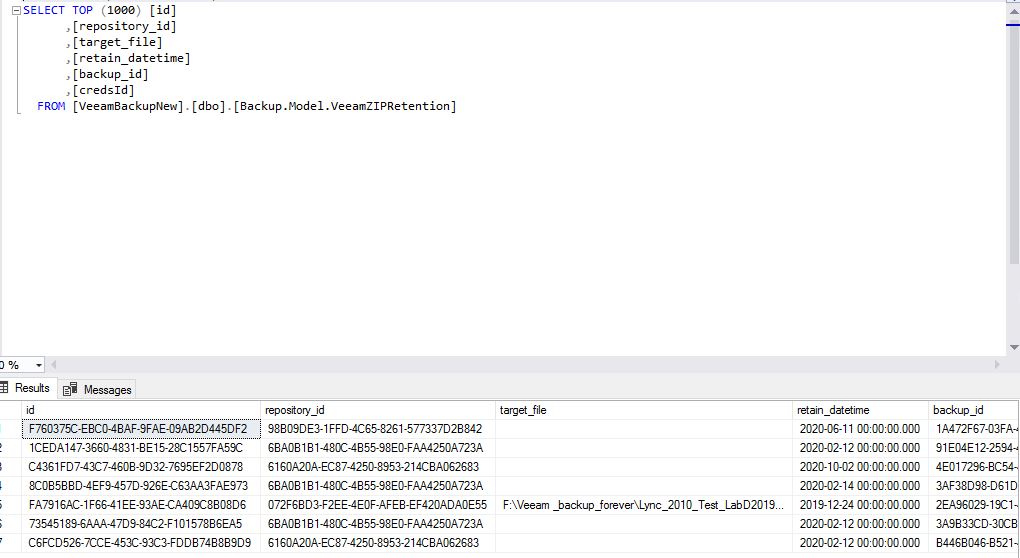 Надеюсь такую важную информацию о бекапах выведут на видное место в новой версии Veeam. (как вариант, чтобы было похоже вкладку Tape Infrastructure — Media Pools — Ваш пул)
Надеюсь такую важную информацию о бекапах выведут на видное место в новой версии Veeam. (как вариант, чтобы было похоже вкладку Tape Infrastructure — Media Pools — Ваш пул)
Опять проблема с сетевым доступом
Привет! Недавно увидел новую ошибку в Veeam, когда не открыты все необходимые сетевые порты. Ошибка следующего вида:
Could not write file [C:\Program Files (x86)\Veeam\Backup Transport\GuestInteraction\VSS\VeeamGuestHelpers\VeeamVixProxy.exe] of size [944208] to the HTTP server
Could not send HTTP request. System error code: 12002
Такой текст у меня возникал, когда я пытался протестировать доступ к серверам при включенном Application-aware processing.
После такой ошибки Veeam не может подключиться к виртуальному серверу через Vmware VIX.
Оказалось все очень просто — необходимо, чтобы от прокси Veeam были доступны сервера ESXi по 443/TCP порту.
Ошибка в Veeam — Agent failed to process method {DataTransfer.SyncDisk}
Столкнулся с такой ошибкой — Error: Failed to open VDDK disk failed because of the following errors: Failed to open disk for read. Failed to upload disk. Agent failed to process method {DataTransfer.SyncDisk} в Veeam Backup and Replication 9.5.
Исправилось у меня легко, так как знал какие были до этого изменения — был подключен новый ESXi-сервер в кластер и не были открыты необходимые порты.
Как исправить? открыть порт 902/TCP от Veeam Proxy до VMware ESXi.
Ошибка «Unable to process: host reboot is required» при бекапе агентом Veeam
Привет! Недавно совершил небольшую ошибку, при обновлении агентов Veeam на одном из серверов с Windows Server 2008R2. на нем у меня стоит агент Veeam версии 2.2.0.589 и я попытался обновить его до версии 3.0.2.1170. Все было бы хорошо, да вот только на сервер редко когда ставится обновления из-за его важности 🙂 Поэтому, когда уже процесс обновления пошел -выяснилось, что в систему ставится обновление «KB3045557«. Всё бы ничего, да вот только после него в консоли Veeam пишется, что серверу требуется перезагрузка. В результате, у меня на 2-ой или 3-ий раз бекап завершился с ошибкой «Unable to process: host reboot is required«. И тут вопрос встал ребром: неужели придется перезагружать сервер, ради того, чтобы выполнить бекап? Я зашел на сервер, вижу, что сервер, не пишет о том, что требуется перезагрузка — уже хорошая новость. Далее я запустил небезызвестный «Process Monitor» и через консоль Veeam запустил сканирование хоста. Далее начал изучать собранную информацию в этой утилите. И вот что получилось: сервис «Veeam Installer Service», под которым работает исполяемый файл VeeamDeploymentSvc.exe лезет в реестр и проверяет значение ключа DotNet_RebootNeeded в ветке реестра HKEY_LOCAL_MACHINE\SOFTWARE\Veeam\Volatile. В моем случае ключ был со значением «1». Поменял это значение на «0» и перезапустил сканирование хоста с консоли Veeam. На этот раз статус хоста стал «Upgrade Required» и уже ночью после очередного бекапа я убедился, что исправление ключа реестра пошло на пользу и бекап снова проходит успешно.
P.S. В моем случае на хосте не стоял драйвер CBT.
Конвертация диска из MBR в GPT (online, Windows)
Понадобилось сконвертировать диск более 2 Tb из MBR в GPT, на котором располагаются файловые шары.
Windows не хочет конвертировать такой диск на лету стандартными средствами оснастки управлениями дисками и утилитой diskpart, поэтому пришлось искать утилиту на стороне. Ею оказалась gptgen, которую можно скачать с SourceForge
Переносом данных при конвертировании онлайн заниматься не надо, что меня вполне устроило. И так план действий:
0. Делаем бекап диска, с которым будем проводить манипуляции (на всякий случай)
1. Запускаем в командной строке утилиту diskpart. Пишем команду list disk и смотрим какой номер диска, который нам нужен. Выходим из diskpart
2. Запускаем утилиту gptgen в командой строке. Она выдает список доступных ключей для запуска.
3. Запускаем команду gptgen -w \\.\physicaldriveX, где X-номер диска из пункта 1. Через несколько секунд появится сообщение, что все прошло успешно.
4. Перезагружаем сервер.
5. Проверяем, на месте ли все корневые папки на диске. В моем случае после конвертации все папки, которые были открыты на общий доступ, были отключены (зашарены). Пришлось их заново расшаривать. NTFS права на папки при этом не были затронуты.
6. Только после всех манипуляций я расширил диск в диспетчере дисков до размера превышающего 2 Tb. Все прошло успешно.
Ошибка в задании резервного копирования Symantec Backup Exec
Initialization failure on: «Microsoft Information Store». Snapshot technology used: Microsoft Volume Shadow Copy Service (VSS).
Snapshot technology error (0xE0008516): The database specified for the snapshot was not backed up because the database was not mounted.
Такая ошибка начала появляться при бекапе серверов Exchange в DAG-e.
Причина ошибки: сменили пароль на учетную запись, под которой запускаются сервисы Symantec Backup Exec.
Помог рестарт служб:
Backup Exec Agent Browser
Backup Exec Device & Media Service
Backup Exec Management Service
Backup Exec Server
и ввод пароля от сервисной учетной записи.
Veeam backup error Code: 1326
Привет! Если вы поменяете пароль для учетной записи, с помощью которой Veeam подключается к серверам для бекапа, то можете столкнуться с ошибкой «Failed to connect to Oracle Details: Failed to logon user Win32 error:Logon failure: unknown user name or bad password. Code: 1326«, даже если он реально правильный. Ошибка возникает после смены пароля в бекапных заданиях, где включена функция «Application-aware processing» и где используется Veeam Agent. Конкретно у меня ошибка была только при ночных системных бекапах серверов SQL, бекапы логов успешно проводились. Для решения проблемы необходимо обновить Veeam Backup and Recovery и Veeam Agent. Их версии должны быть 9.5.4.2866 и 3.0.2 соответственно. В моем случае понадобилось только обновить агенты и даже не пришлось перезагружать сервера.