Проблема:
Скачал и установил готовый appliance от zabbix . Но с ним есть проблемы — при создании снапшота виртуальная машина перестает работать, а при запуске ее вновь ошибка Object type requires hosted I/O Failed to start the virtual machine. Module Disk power on failed. Cannot open the disk ‘/vmfs/volumes/5bcda19c-7fdf91a6-d95f-2c768aae1eb8/zabbix/zabbix_appliance-6.4.10-disk1.vmdk’ or one of the snapshot disks it depends on. После этого ее удается запустить только после исправления виртуального диска командой vmkfstools -x repair. Пытался изменить настройки виртуальной машины, вместо ide контроллера для диска выбирал SCSI, ошибка Unsupported or invalid disk type 7 for ‘scsi0:0’. Ensure that the disk has been imported. Failed to start the virtual machine. Module DevicePowerOn power on failed. Unable to create virtual SCSI device for scsi0:0, ‘/vmfs/volumes/5bcda19c-7fdf91a6-d95f-2c768aae1eb8/zabbix/zabbix_appliance-6.4.10-disk1.vmdk’. Снапшот на выключенной виртуальной машине делается без ошибок.
VMware ESXi, 7.0.3, 21424296
vCenter 7.0.3 22357613
Решение:
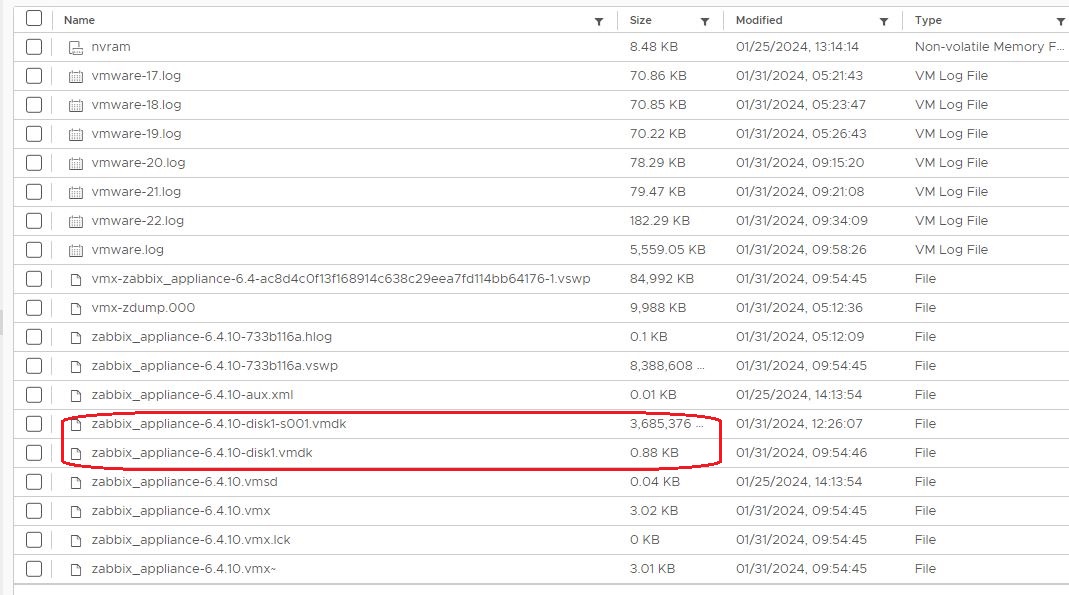
Смотрим что творится с дисками виртуальной машины:
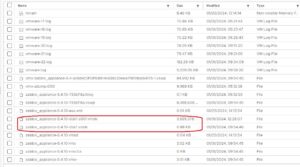
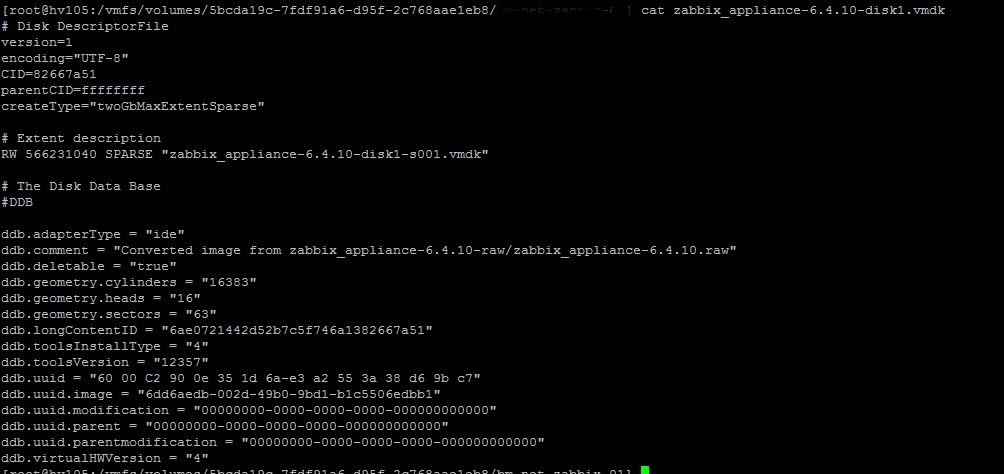
Открываем содержимое диска, которое занимает меньше всего пространства и видим:
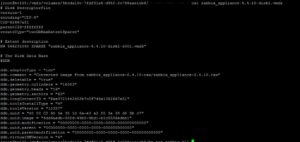
Видим, что тип диска Sparse, который имеет формат split, делящий диск на 2ГБ куски. Такой тип диска поддерживается в работе Vmware Workstation. Чтобы корректно работать с ним на VMware Esxi необходимо выполнить конвертацию диска:
vmkfstools -i zabbix_appliance-6.4.10-disk1.vmdk zabbix_appliance-6.4.10-disk1_new.vmdk
Добавляем новый диск к ВМ, вместо старого
Удаляем старый диск вместе с дескриптором:
vmkfstools -U zabbix_appliance-6.4.10-disk1.vmdk
 Статья на сайте разработчика мне никак не помогала, т.к. она была старая и решение той проблемы было выполнено давно.
Статья на сайте разработчика мне никак не помогала, т.к. она была старая и решение той проблемы было выполнено давно.